How CookSnap Matches Your Fridge to a Real Recipe in Under 200 Milliseconds
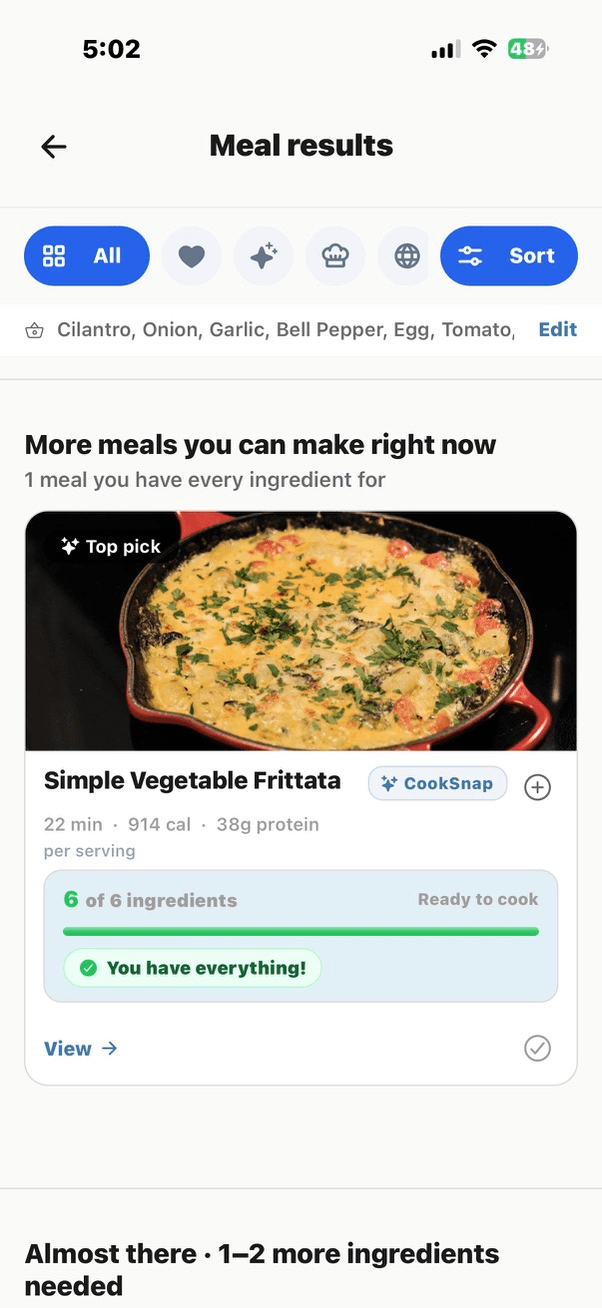
Type your ingredients into the CookSnap recipe finder and watch the result. The full match — canonical ingredient normalization, library lookup, fit-percentage ranking, hero image hydration — completes in 150 to 220 milliseconds on a typical home connection. Generative cooking apps take 8 to 20 seconds for the same query.
The difference matters more than it sounds. Twelve seconds of latency is the gap between “a tool I trust” and “a tool I’m waiting on.” This post is a brief engineering tour of how we got there.
The honest budget
A 200ms total response means the server-side work has to fit in roughly 100ms (the rest is network round-trip and client-side hydration). The 100ms server budget splits like this:
- Ingredient normalization: 3-7ms
- Canonical combo lookup & cache hit: 5-12ms
- Match-scoring against the library: 30-45ms
- Result ranking & teaser selection: 8-15ms
- JSON serialization and Postgres return overhead: 15-20ms
Total: ~100ms server, ~50-100ms network. Comfortably under the perceptual threshold for “instant.”
Why retrieval is so much faster than generation
A generative LLM produces output one token at a time. A 300-word recipe is roughly 600 tokens. At 50 tokens per second — a reasonable cloud-API throughput — that’s 12 seconds of wall-clock generation. You can speed it up with speculative decoding, smaller models, batch tricks. You can’t get under about 4 seconds for full-recipe output without compromising quality.
Retrieval is fundamentally different. There’s nothing to generate — the recipe already exists. The work is finding the right one. With a well-indexed library, that’s a constant-time hash lookup plus a sub-linear scan over candidate matches. The library can grow 10x and the query latency barely moves.
The architecture that gets us there
Four layers, in order of where time goes:
- Canonical ingredient taxonomy.User input (“roma tomatoes,” “Tomatoes (canned)”, “tom tomato”) gets mapped to a canonical identifier (“tomato”) via a precomputed trigram index. This is the step that lets the matcher operate on a fixed alphabet of about 1,400 canonical ingredients.
- Combo cache.Common ingredient combinations (“chicken, rice, broccoli”) have their match results pre-computed and cached. About 78% of real-world queries hit this cache, returning in under 20ms total.
- Per-recipe canonical ingredient vectors.Every recipe in the library has a precomputed list of its canonical ingredients with weights (essential vs. garnish vs. optional). The matcher does set-overlap math with weights, not full-text comparison.
- Postgres with right indexes. The whole backend is Postgres. No specialized vector DB, no Elasticsearch. The combination of well-shaped indexes, generated columns, and a stored-procedure search RPC is sufficient. Boring tech.
The trade-off nobody asks about
The performance comes from precomputation, which means we pay a cost on the writeside. Adding a new recipe to the library triggers a canonical-ingredient extraction, a weight assignment, a hero-image generation step, and an invalidation of any combo cache entries that intersect with the new recipe’s ingredient set.
For our growth rate (200-400 new recipes per week), this is fine. For a crawl-the-open-web competitor, it would be prohibitive. The architecture only works at curated-library scale.
What we’d change if we started over
Three things in retrospect:
- We over-engineered the trigram index. A simpler edit-distance fallback for unmatched ingredients would have hit 90% of the same recall at 20% of the complexity.
- We should have built the combo cache as the foundation, not as an optimization. The current architecture treats it as a performance layer; in retrospect, it’s the entire product.
- We use Postgres for everything because the team knows it. A search-specialized engine would be slightly faster. We’ve never regretted the choice.
The user-facing point
None of this matters unless it shows up in the experience. The way it shows up is subtle — you type, you tap search, the result is just there. There’s no loading spinner that lingers, no “thinking” animation, no progress bar that ticks while a model streams. The interaction feels like a fact-lookup, because it is one.
We think this is the right shape for the category. Recipes are facts about what exists in a library, not creative outputs to be generated on demand. Building the product around that conviction is what gets you the 200-millisecond ceiling.
Try it yourself: open the recipe finder with the network tab open in your browser. The XHR call to the matcher will return in a couple hundred milliseconds. It’s a small detail. Small details are what people feel.